Work Hours
Monday to Friday: 8am – 6pm
Weekend: 10am – 2pm

Since the beginning of microprocessors, there can be only one task (set of computation) in time. If we need to made more than one task in a certain time, we need to wait until 2001 when the first commercial multicore processor was released. Or did we?

Let’s imagine a situation where many people want to use a system at the same time. Each person has different programs they want to run. Each of these programs is like a job or task. So, if we want to handle this situation well, we need a system that can do many things at once.
Think about watching a video. It’s just a bunch of pictures shown quickly to make it look like things are moving. Similarly, on a computer with only one processor, we can do one task at a time, but only for a very short moment. Each task is like one picture. Doing them quickly gives the feeling of doing many things at the same time.
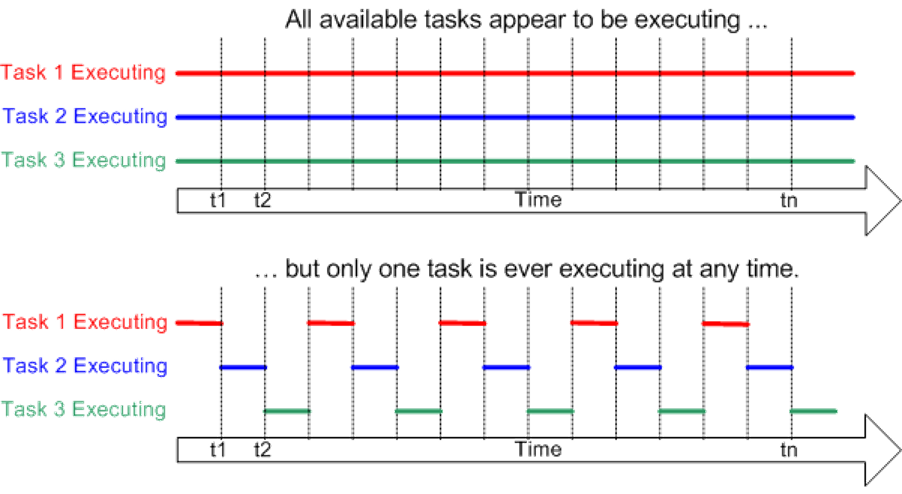
What if some tasks are more important than others? They need to be done first. And what if a task is waiting to get information from somewhere else?
Handling these situations is the job of the scheduler. It’s like a manager in the computer’s operating system (yes, we’re basically making our own operating system here). The scheduler decides when each task gets its turn to run.
Consider an example:
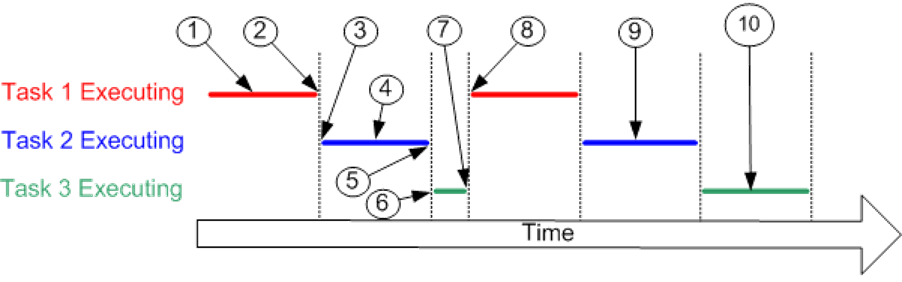
Does that sound simple? Let’s go a bit deeper into the processor. Every task uses the processor and gets information from the memory. All these resources, like processor registers, stack, memory, etc., are what we call the task’s context.
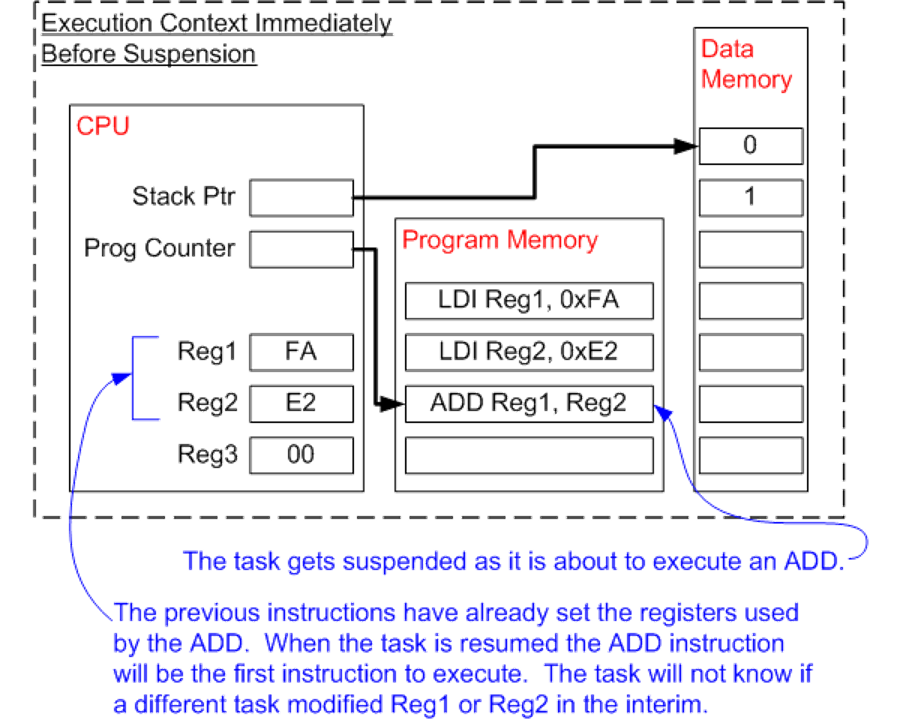
Looking from the point of view of the task, it is a simple piece of code. It doesn’t know when, how much it will be resumed/stopped, or that it is happening at all. For example, a task is stopped just before a sum is executed on two registers in the processor. While another task is executing, the contents of these registers may be changed. In view of this, before each stoppage of the thread, we must save the state of the registers, then before resuming it – restore them. This is called thread switching. As you can see, this is quite expensive in terms of time and resources. I won’t explain here how data exchange between tasks, especially in the case of multi-core or multi-processor environments (yes, every PC has several processors, such as a CPU and GPU). The basics of how tasks work we have.
Now that we know how it works at the processor level, let’s move up a level.
Vocabulary in C#:
Let’s assume a situation where we have a PC application, using database access. Each connection to the database, creates a new thread for us. Now let’s give many users, many operations, and we end up with a pool of 3000 threads. As you can easily imagine, hardly any machine will be responsive. It will spend most of its time not performing tasks, but switching threads.
So how can we remedy this? We can create a pool of threads (say 120) and use this pool. If we run out of elements, we have to wait for the previous one to be released. As you can see, this is not a very scalable approach. So what could be the solution? Asynchronicity.
Synchronous operation is easy to understand. That’s why it’s the only thing they teach in schools (or at least they did when I went to school 100 years ago).
Suppose we want to retrieve data from a database. We open a connection, send a query, wait for a response and execute the rest of the program. Waiting for the answer, blocks our thread. In view of this, to get 3000 queries, we need 3000 threads.
What if we did it differently? We send those 3,000 requests in one thread, but we don’t wait for a response. We only respond to them when they come. What’s more, if we had a sufficiently intelligent scheduler that knows when we need to perform an operation in a separate thread/core/processor, our application, operating theoretically on a single thread, would be scalable and responsive. Well, .NET has such a scheduler.
We already know how to create asynchronous communication in applications. This requires changing the approach from step-by-step, to task-based thinking.
So we know how we can use asynchronicity in C#. async + await + CancellationToken. What is CancellationToken? In our example from above, we created 3000 database queries, but suddenly our application doesn’t want those results anymore because the user has quit the application. So it will not wait for the response. And the database prepares the data. For 3000 queries. Consuming resources. This is what CancellationToken is used for. If application does not wait anymore, we can exit requesting process.
When communicating between applications, we have two approaches to communication. Synchronous and asynchronous. And it’s not that if we want a response, we have to use synchronous, and when we don’t, we have to use asynchronous. In addition, we may want to communicate one to one (121) or one to many (12~).
We can find in practical applications four approaches to interaction:
1. “Fire and forget” is sending a message and not waiting for a reply. The sender just sends the message and continues with its own work, not bothered about what happens next. It’s good when you don’t need an immediate response and just want to let someone know something or ask them to do something without waiting for them to finish.

2. “Question and answer” communication pattern is like having a conversation. One part, the questioner, asks a question, and the other part, the responder, gives an answer. It’s a back-and-forth interaction where the questioner waits for the responder to reply before continuing. This pattern is useful when you need specific information or want to make sure a task is completed successfully.

3. “Question and asynchronous answer” communication pattern, it’s similar to asking a question, but instead of waiting right there for an immediate answer, you continue with your own work. The service receiving the question responds when they have the answer, and you can carry on with your tasks in the meantime. This approach is handy when you don’t want to stop everything just to wait for a reply, making it more flexible and efficient for certain situations. It is very handy, when we need to ask several services for several things, but we can continue only when we collect all answers.

4. “Publish and subscribe” communication pattern, it’s like broadcasting information. One part, the publisher, sends out messages or updates without knowing who exactly will receive them. The other part, the subscriber, expresses interest in certain types of messages and gets notified whenever there’s new information. It’s a way for different parts of a system to stay informed about changes without directly communicating with each other. This pattern is helpful for creating flexible and loosely connected systems.
